A simple semantic search with Python and FastAPI


In this article, we will implement a simple semantic search using Python's FastAPI and Sentence Transformer. First, let's understand what semantic search is.
What Semantic Search?
Semantic search is a data searching technique that uses NLP (Natural Language Processing) to understand the meaning and context of user's search queries and provide more relevant results.
A semantic search engine utilizes a vector database to store text embeddings/vectors. It uses indexing algorithms to convert text data into vectors, which are then stored in the database for search purposes. When a user submits a search query, the query is also converted into a vector. The search engine then performs a similarity process to retrieve relevant results from the database.
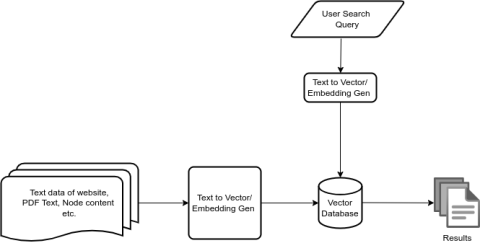
Obviously, there are various processes that handle data before converting and storing it in the vector database, such as cleaning and preprocessing the data, and removing stop words, among others.
There are several vector indexing algorithms such as FAISS and HNSW. However, in this article, we will use Sentence Transformer, which is capable of utilizing various models to generate vectors. We can see the model list here.
Advantage of having a semantic search
Semantic search understands the context and meaning of search queries, thereby providing more relevant results.
Okay, Let's start with our development. we will develop a simple semantic search application that has the following processes.
- Preprocess of data.
- Convert data to vector and store it locally.
- Preprocess search query.
- Generate results.
Application Architecture
Project/
│
├── app/
│ ├── base/
│ ├── ├── embeddings.py
│ ├── ├── models.py
│ ├── data/
│ ├── ├── data_merger.py
│ ├── ├── data_processor.py
│ ├── ├── data.csv
│ ├── data/
│ ├── ├── search.py
│ ├── __init__.py
│ ├── main.py
│ ├── security.py
│ ├── util.py
│
├── requirements.txt
├── run.py
├── streamlit.py
└── test_main.httpPreprocess of data.
Since everyone has their specific data, the data processing script can vary. I have user data in CSV format spread across different files, so I merge all data into one CSV file. Next, I convert the data into meaningful sentences and store them in a separate column within that CSV. We use this data for further processing before creating vectors.
Convert data to vector and store it locally.
On application startup, we will convert the CSV data to vectors and save them locally. If the local file does not exist, we will generate the vectors; otherwise, we will load them from the local file.
@app.on_event("startup")
async def load_data():
global merged_df, corpus_embeddings
tensor_file_path = 'app/data/corpus_embeddings.pt'
# Read CSV data - Needed to produce results.
merged_df = pd.read_csv('app/data/merged_tables_live.csv')
if os.path.exists(tensor_file_path):
# Load tensors from file
corpus_embeddings = torch.load(tensor_file_path)
else:
corpus_embeddings = get_corpus_embeddings(merged_df['combined_text'].tolist())
# Save tensors to file
torch.save(corpus_embeddings, tensor_file_path)Below function is used to convert data to vector/tensor
from sentence_transformers import SentenceTransformer
# Load model
model = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2')
def get_corpus_embeddings(corpus: list):
return model.encode(corpus, convert_to_tensor=True)
def get_embeddings(text: str):
return model.encode(text).tolist()
Preprocess search query
This step involves cleaning and preprocessing the search query provided by the user. We have developed a utility function for this purpose, which can be utilized in various parts of our application.
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem import WordNetLemmatizer
import re
nltk.download('punkt')
nltk.download('stopwords')
nltk.download('wordnet')
# Text preprocessing
def preprocess_text(text):
# Remove punctuation
text = re.sub(r'[^\w\s]', '', text)
# Tokenization
tokens = word_tokenize(text)
# Stopword removal and lowercase
tokens = [token.lower() for token in tokens if token.lower() not in stopwords.words('english')]
# Lemmatization
lemmatizer = WordNetLemmatizer()
tokens = [lemmatizer.lemmatize(token) for token in tokens]
return " ".join(tokens)Generate results
Our search function will generate results by calculating the cosine similarity between the search query and the vector database. There are various other methods to calculate similarity but cosine similarity is widely used and so we will utilize it.
from sentence_transformers import util
import numpy as np
import torch
from app.base.embeddings import model
from app.util import preprocess_text
def semantic_search(query: str, corpus_embeddings: torch.Tensor, top_n: int = 10):
query = preprocess_text(query)
query_embedding = model.encode(query, convert_to_tensor=True)
cos_scores = util.pytorch_cos_sim(query_embedding, corpus_embeddings)[0]
top_results = np.argpartition(-cos_scores, range(top_n))[:top_n]
return top_results, cos_scores@app.post("/search", response_model=List[dict])
async def search(query: TextData):
top_results, cos_scores = semantic_search(query.input, corpus_embeddings)
results = []
for idx in top_results:
idx = int(idx)
results.append({
"User ID": merged_df.iloc[idx]['User ID'].item(),
"Full Name": merged_df.iloc[idx]['Full Name'],
"Email": merged_df.iloc[idx]['Email'],
"Designation": merged_df.iloc[idx]['Designation'],
"Similarity Score": cos_scores[idx].item()
})
return resultsNow, we can perform our search using /search endpoint.
Here is the project's GitHub repository. Check the repository readme to set up and try it in your local.
Additional
Here is an additional endpoint to return vector data of provided text so that it can be stored and used locally.
@app.post("/embed")
async def get_embedding(data: TextData, credentials: HTTPBasicCredentials = Depends(security)):
verify_credentials(credentials)
try:
# Generate embeddings
embedding = get_embeddings(data.input)
return {"embedding": embedding}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))We are using basic authentication; however, it needs to be stronger for production.
Conclusion
The above implementation of semantic search will provide a basic understanding of how semantic search works. The result accuracy and quality will depend on the data we provide to the search engine, as well as the model we choose for our search.